前幾篇說明了 ES as Vector DB 的使用,在 AI 的應用中,Vector DB 主要的使用場景是 RAG—Retrieval Augmented Generation。RAG 的意思是在 Generative AI Model 外掛知識庫,因為大部分的 LLM 的訓練是基於目前網路上的公開資料,當你需要 AI 針對企業內(例如客服、tech support 等)或是特定知識庫的內容進行回覆時,AI 需要先『讀過』這些資料,把存有特定內容(可以是影片、圖片、文字等)提供給 AI 作為額外知識庫的內容來進行作業,就是 RAG。
那要怎麼結合 LLM & ES 做 RAG 呢?我摘要 OPENAI 這篇文章的部分作為說明:
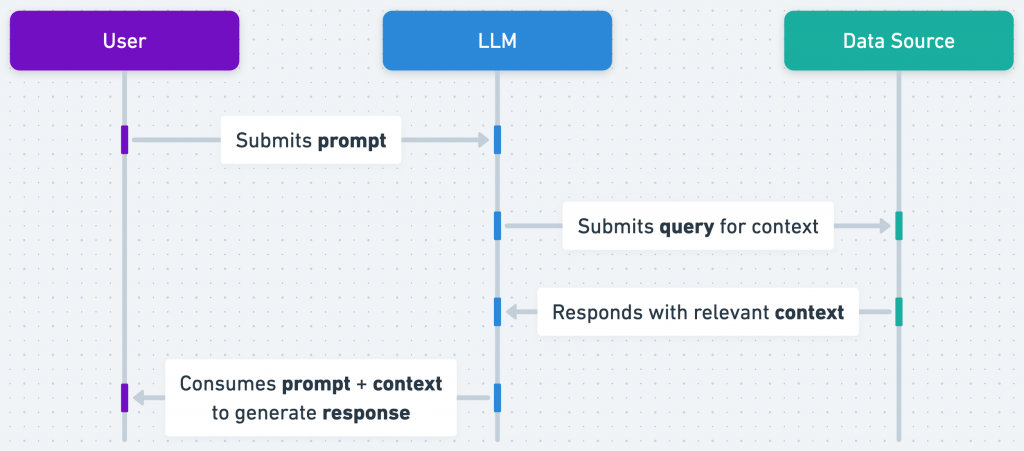
basic RAG workflow, source: https://help.openai.com/en/articles/8868588-retrieval-augmented-generation-rag-and-semantic-search-for-gpts
先從上面這張圖說明 LLM 和 RAG 的互動流程開始,當 User 送出 prompt 指令給 LLM, LLM 除了理解 Prompt 並搜尋自己的知識庫外,也會送出 query 給 Data Source 取得相關的資料(context);Data Source 根據 query 回傳結果給 LLM,LLM 將 User Prompt 和 Context 消化運算之後回傳 Response 給 User。
文章中舉了一個使用 LLM + RAG 建立客服 chatbot 的流程:
將文章存在 vector db
當 user 問 chatbot 問題時,會執行下的流程:
這個流程,是不是看起來很熟悉啊?
前幾篇的內容已經實作了大部分的步驟,包含將文章存在 vector db 內、搜尋和 query 相似的語句、得到相近的字串等。
就差最後一步把 vector search 得到的結果加上 prompt 丟給 LLM 來回問題,所以我們接下來的幾篇就來完成這件事吧。


 iThome鐵人賽
iThome鐵人賽